![]()
The IAIFI Summer Workshop brings together researchers from across Physics and AI for plenary talks, poster sessions, and networking to promote research at the intersection of Physics and AI. We will also accept submissions for contributed talks and/or posters.
Registration and abstract submissions are now open for the 2026 IAIFI Summer Workshop. Register here by July 31, 2026 and submit a talk or poster here by noon Boston time on June 8, 2026.
- The 2026 Summer Workshop will be held August 10–14, 2026
- Location: MIT, Cambridge, MA
RegisterSubmit a talk/posterAgenda Speakers AccommodationsFAQ Past Workshops
About
The Institute for Artificial Intelligence and Fundamental Interactions (IAIFI) is enabling physics discoveries and advancing foundational AI through the development of novel AI approaches that incorporate first principles, best practices, and domain knowledge from fundamental physics. The goal of the Workshop is to serve as a meeting place to facilitate advances and connections across this growing interdisciplinary field.
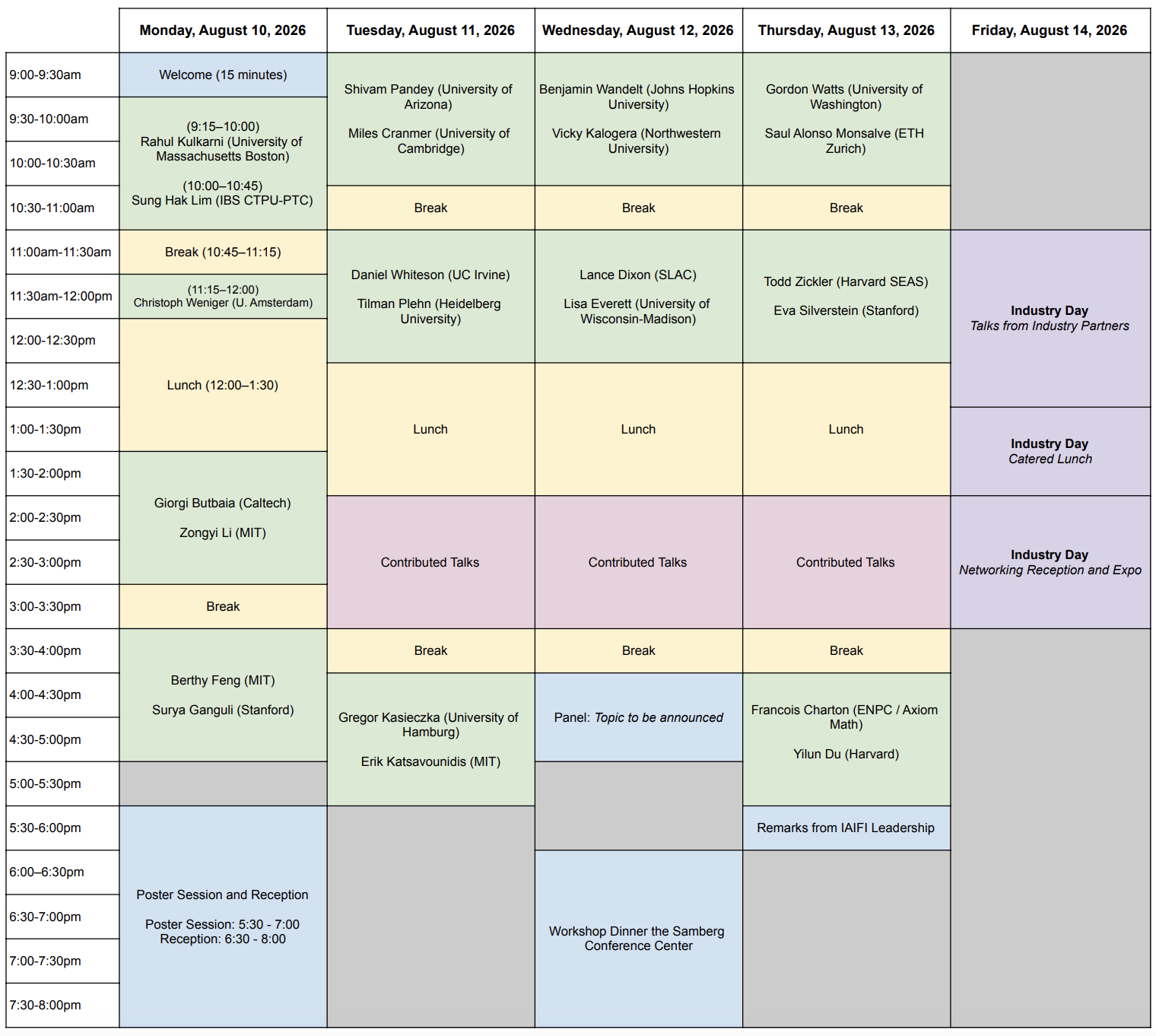
Agenda
The schedule is subject to change. More details to be provided later in July.
Regarding IAIFI Industry Day Day on Friday, August 14: This will be an excellent networking opportunity between Workshop attendees, IAIFI members, and industry partners. Industry participants will include employees of Glasswing Ventures, QuEra Computing, Stripe, Draper, Extropic, Amazon, MathWorks, Mitsubishi Electric Research Laboratories (MERL), Physical Superintelligence PBC, Agentoid, Fine Structure Ventures, Engine Ventures, Extropic, and First Principles.
Plenary Speakers
Additional speakers will be added as they are confirmed.






















Accommodations
We have established discounted rates for August 9–August 15, 2026 at the following hotels:
-
Le Meridien, 20 Sydney St, Cambridge, MA 02139.
$199 nightly rate
Deadline to book: July 9, 2026
-
Boston Marriott Cambridge, 50 Broadway, Cambridge, MA 02142.
$219 nightly rate
Deadline to book; Friday, July 17, 2026
-
Residence Inn by Marriott, 120 Broadway, Cambridge, MA 02142.
$219 nightly rate
Deadline to book; Tuesday, July 21, 2026
FAQ
- Who can attend the Summer Workshop? Any researcher working at or interested in the intersection of physics and AI is encouraged to attend the Summer Workshop.
- What is the cost to attend the Summer Worskhop? The registration fee for the Summer Workshop is 200 USD and includes a welcome dinner, as well as coffee breaks and snacks.
- If I come to the Summer School, can I also attend the Workshop? Yes! We encourage you to stay for the Workshop and you can stay in the dorms for both events if you choose (at your expense).
- Will the recordings of the talks be available? We plan to share the talks on our YouTube channel.
2026 Organizing Committee
- Will Detmold, Co-Chair (MIT)
- Bill Freeman, Co-Chair (MIT)
- Sam Bright-Thonney (IAIFI Fellow)
- Akshunna Dogra (IAIFI Fellow)
- Berthy Feng (IAIFI Fellow)
- Mathis Gerdes (IAIFI Fellow)
- Juvenal Bassa (UPRM)
- Yize Dong (Harvard)
- Franc O (Northeastern)
- Sneh Pandya (Northeastern)
- Shelley Tong (MIT)
- Lana Xu (MIT)
- Xiaoyuan Zhang (MIT)
- Marisa LaFleur (IAIFI Managing Director)
- Thomas Bradford (IAIFI Project Coordinator)